El enrutamiento de solicitudes de IA es una capacidad de infraestructura diseñada para gestionar recursos de inferencia multimodelo. A medida que los modelos de lenguaje de gran tamaño como GPT, Claude, Gemini y DeepSeek siguen evolucionando, un número creciente de aplicaciones de IA integran simultáneamente múltiples modelos. Elegir de forma inteligente entre distintos modelos se ha convertido en un tema crítico en el diseño de sistemas de IA.
Gate.AI se sitúa entre las aplicaciones y los servicios de modelos, actuando como un Gateway de IA y una capa de enrutamiento de modelos. A medida que las arquitecturas multimodelo se convierten en el estándar del sector, el enrutamiento de modelos influye no solo en el rendimiento del sistema, sino también en el control de costos, la estabilidad del servicio y las capacidades autónomas de los agentes de IA.
¿Qué es el enrutamiento de solicitudes de IA?
Como mecanismo de programación que selecciona automáticamente un modelo objetivo en función de las características de la tarea, el enrutamiento de solicitudes de IA en arquitecturas tradicionales suele implicar que una aplicación llame a un único modelo fijo para completar tareas de inferencia. En una arquitectura multimodelo, cada modelo ofrece ventajas distintas: capacidad de razonamiento, generación de código, procesamiento de texto largo o eficiencia de costos. La capa de enrutamiento de modelos analiza el contenido de la solicitud y la envía al modelo más adecuado para su ejecución, optimizando así la utilización general de los recursos.
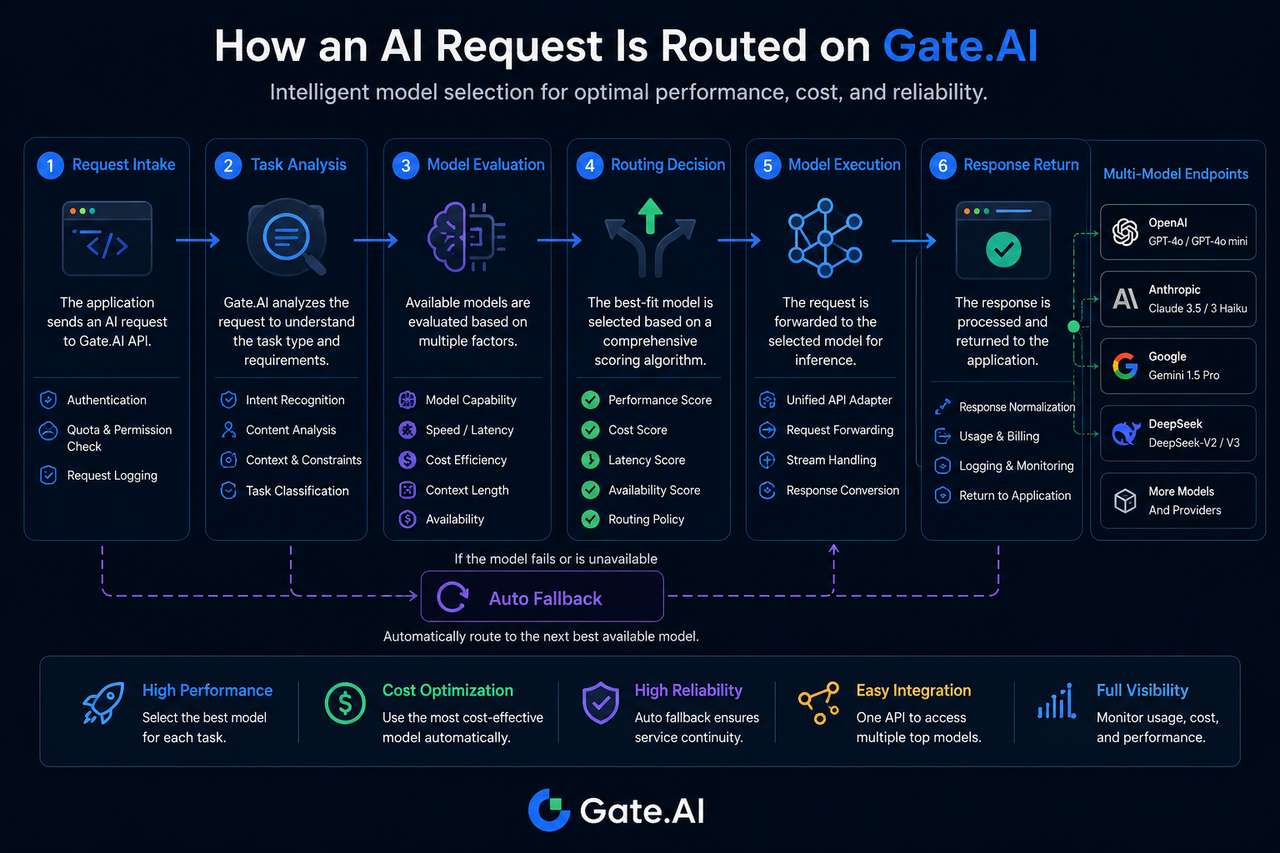
Paso 1: La solicitud de IA entra en Gate.AI
Un proceso de enrutamiento comienza con la fase de acceso de la solicitud. Cuando una aplicación envía una solicitud, primero llega a la capa de Gateway de Gate.AI. En ese momento, el sistema verifica la información de identidad, comprueba los permisos de acceso y registra los parámetros de la solicitud.
El contenido de la solicitud suele incluir:
- Entrada del usuario
- Configuración del modelo
- Límites de tokens
- Requisitos de formato de respuesta
- Estrategia de invocación
Tras la verificación, la solicitud pasa a la siguiente fase de análisis.
Paso 2: El sistema analiza el tipo de tarea
La identificación de la tarea es un componente clave del enrutamiento de modelos. Gate.AI determina el tipo de tarea según las características de la solicitud, por ejemplo:
- Conversación general
- Resumen de texto largo
- Creación de contenido
- Generación de código
- Análisis de datos
- Llamadas a herramientas de agentes
Cada tarea exige capacidades de modelo muy distintas. Una identificación precisa de la tarea agiliza el proceso posterior de emparejamiento de modelos.
Paso 3: Evaluación y emparejamiento de capacidades de los modelos
La fase de evaluación determina el rango de modelos candidatos. El sistema consulta la base de datos de capacidades de modelos para filtrar los modelos disponibles en ese momento.
Las dimensiones de evaluación suelen incluir:
- Capacidad de razonamiento
- Longitud de contexto
- Velocidad de respuesta
- Capacidad de llamada a herramientas
- Soporte multimodal
- Nivel de costo
Por ejemplo, las tareas de razonamiento complejo pueden priorizar modelos con mayor capacidad de razonamiento, mientras que las de procesamiento de documentos largos suelen favorecer modelos que admitan ventanas de contexto ultra largas.
Paso 4: Generar la decisión de enrutamiento
La fase de decisión determina el modelo de ejecución final. Una vez identificados los modelos candidatos, el sistema los puntúa combinando múltiples métricas.
Los factores de referencia habituales son:
Rendimiento del modelo
El rendimiento del modelo determina la calidad de la tarea. Los problemas complejos suelen requerir un razonamiento lógico más sólido, mientras que las tareas simples no necesitan el modelo de mayor rendimiento.
Latencia de respuesta
La velocidad de respuesta afecta directamente a la experiencia del usuario. En escenarios de interacción en tiempo real, los modelos de baja latencia suelen recibir mayor prioridad.
Costo de invocación
Los costos de inferencia varían entre modelos. Cuando varios pueden completar la misma tarea, el sistema suele priorizar el que ofrezca mayor eficiencia de recursos.
Disponibilidad del servicio
El estado del modelo también es un factor importante. Si un modelo tiene limitación de tasa, presenta fallos o está congestionado, el sistema reduce automáticamente su prioridad.
Paso 5: Solicitud enviada al modelo objetivo
Una vez tomada la decisión de enrutamiento, la solicitud se reenvía al modelo objetivo. En esta etapa, Gate.AI maneja de forma uniforme las diferencias de interfaz entre los distintos proveedores de modelos. Los desarrolladores de aplicaciones no necesitan crear interfaces separadas para cada modelo. Una capa de acceso unificada reduce la complejidad del desarrollo y mejora la escalabilidad del sistema.
Paso 6: El modelo genera el resultado y lo devuelve
Una vez que el modelo objetivo completa la inferencia, el resultado se devuelve a Gate.AI. Gate.AI estandariza la respuesta para garantizar estructuras de datos consistentes entre modelos. Un formato de salida unificado reduce el trabajo de adaptación en la capa de aplicación y simplifica la integración posterior. El resultado final se devuelve a la aplicación o al agente de IA.
¿Qué sucede cuando el modelo objetivo no está disponible?
La falta de disponibilidad de un modelo es algo habitual en un ecosistema multimodelo. Si el modelo objetivo agota el tiempo de espera, tiene limitación de tasa o experimenta anomalías en el servicio, Gate.AI puede activar un proceso de respaldo automático. El sistema vuelve a seleccionar un modelo de respaldo siguiendo políticas preestablecidas para continuar con la tarea. Este mecanismo reduce el riesgo de puntos únicos de fallo y mejora la continuidad general del servicio.
Para obtener más información sobre este proceso, consulta "¿Qué sucede cuando falla un modelo de IA? Un análisis completo del flujo del mecanismo de respaldo automático de Gate.AI".
Ejemplo de un proceso de enrutamiento de solicitudes de IA
El siguiente ejemplo muestra un flujo típico para una tarea de generación de contenido:
| Fase |
Acción del sistema |
| Acceso de la solicitud |
La aplicación envía la solicitud de generación |
| Análisis de la tarea |
Identificada como creación de contenido de texto largo |
| Filtrado de modelos |
Seleccionar modelos candidatos que admitan contexto largo |
| Decisión de enrutamiento |
Puntuar según rendimiento, costo y latencia |
| Ejecución del modelo |
Solicitud enviada al modelo objetivo |
| Procesamiento del resultado |
Devolver salida estandarizada |
| Recuperación de fallos |
Cambiar automáticamente al modelo de respaldo si es necesario |
Este proceso suele completarse en un tiempo muy breve y los usuarios no suelen percibir la selección del modelo que ocurre en segundo plano.
Resumen
Como capacidad principal del Gateway de IA, el enrutamiento de solicitudes de IA selecciona de forma dinámica el modelo más adecuado para ejecutar una tarea entre múltiples modelos de lenguaje de gran tamaño. Frente a la invocación fija de un solo modelo, el enrutamiento de modelos aprovecha al máximo las fortalezas de cada uno, mejorando la flexibilidad, la estabilidad y la utilización de recursos del sistema.
En la arquitectura de Gate.AI, una solicitud de IA pasa por varias etapas: acceso de la solicitud, identificación de la tarea, evaluación del modelo, decisión de enrutamiento, ejecución del modelo y devolución del resultado.
Preguntas frecuentes
¿Por qué Gate.AI necesita enrutamiento de modelos?
Gate.AI conecta múltiples ecosistemas de modelos de IA, donde cada modelo destaca en razonamiento, generación de código, procesamiento de texto largo u otras áreas. El enrutamiento de modelos selecciona automáticamente el más adecuado según los requisitos de la tarea.
¿Puede una sola solicitud de IA llamar a múltiples modelos al mismo tiempo?
Normalmente, una única solicitud de IA la ejecuta un único modelo objetivo. Sin embargo, en algunos escenarios complejos se puede usar un patrón de colaboración multimodelo, donde distintos modelos gestionan diferentes partes de la tarea.
¿Qué factores se consideran principalmente en las decisiones de enrutamiento de IA?
Las decisiones de enrutamiento de IA suelen considerar múltiples factores: rendimiento del modelo, velocidad de respuesta, costo de inferencia, longitud de contexto, capacidad de llamada a herramientas y disponibilidad del servicio.
¿Cuál es la diferencia entre enrutamiento de modelos y balanceo de carga?
El balanceo de carga se ocupa principalmente de la distribución del tráfico, mientras que el enrutamiento de modelos se centra en el emparejamiento de capacidades. El enrutamiento de modelos selecciona el modelo más adecuado según las características de la tarea, no simplemente distribuye el tráfico de solicitudes.








