Avec l’essor de la demande en données comportementales issues du monde réel, portée par la Robotique IA et l’IA incarnée, les réseaux de données décentralisés s’imposent comme un pilier essentiel de l’infrastructure IA.
Caspius et les plateformes de données IA classiques assurent toutes deux la collecte de données d’entraînement pour l’IA, ce qui les rend fréquemment comparées. Bien que les deux soutiennent l’entraînement des modèles d’IA, elles se distinguent fondamentalement par le contrôle des données, la logique de répartition de la valeur et l’architecture de l’écosystème.
Qu’est-ce que Caspius ?
Caspius est un protocole d’infrastructure de données taillé sur mesure pour la Robotique IA et l’IA incarnée. Il rassemble des données comportementales du monde réel via un réseau ouvert, fournissant ainsi la matière première nécessaire à l’entraînement des modèles d’IA.
Le projet cible les vidéos à la première personne, les trajectoires de mouvement et les données d’interaction avec l’environnement indispensables à l’apprentissage des robots. Ces données permettent aux systèmes robotiques de maîtriser l’exécution d’actions concrètes, le raisonnement spatial et le retour sensoriel.
À la différence des plateformes classiques, Caspius exploite les mécanismes d’incitation de la blockchain, permettant à tout utilisateur de contribuer des données. En téléchargeant des données d’entraînement valides, les utilisateurs obtiennent des récompenses en Tokens CAS.
Dans sa position, Caspius se rapproche davantage des réseaux de données IA ouverts et des projets d’infrastructure DePIN.
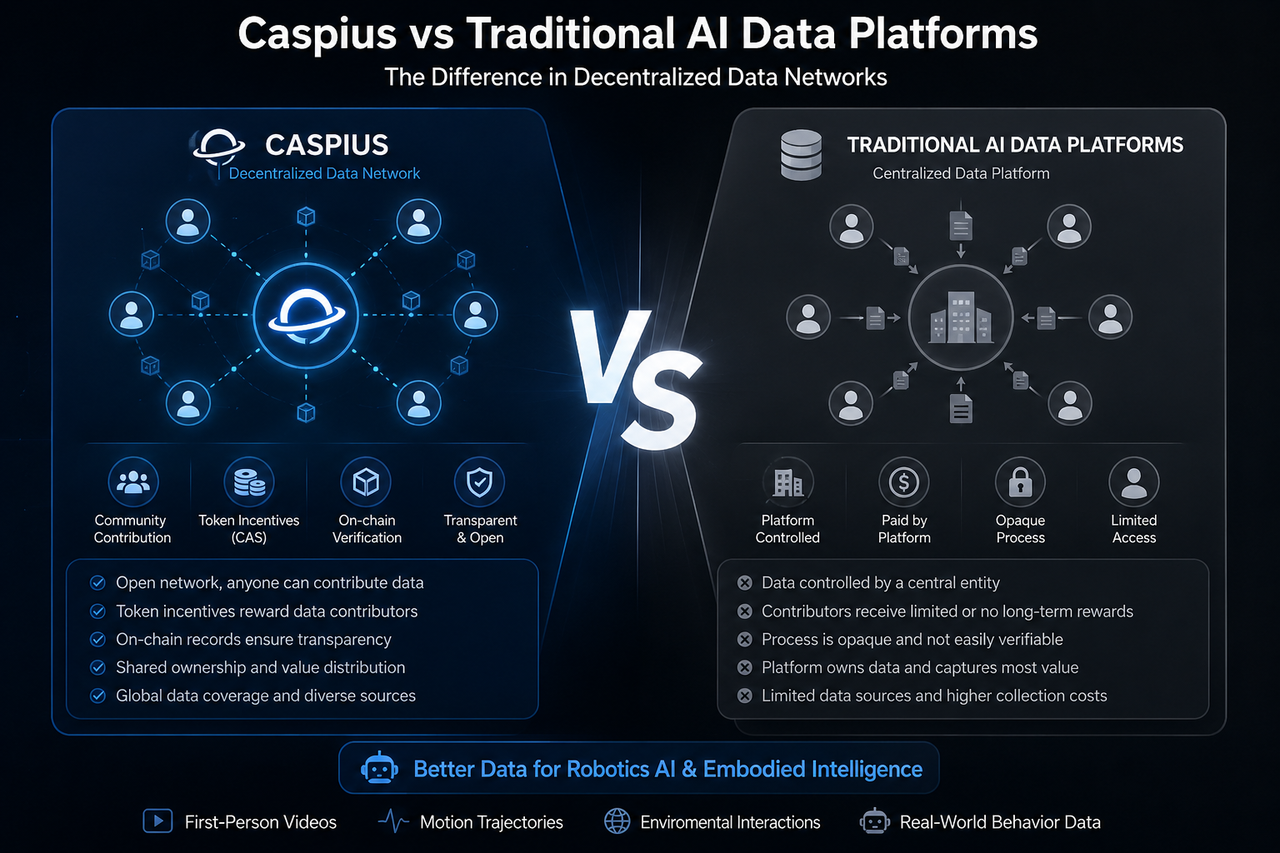
Les plateformes de données IA classiques sont généralement gérées par des entreprises centralisées qui assurent la collecte, l’annotation, l’organisation et la commercialisation des données.
Dans ce modèle, la plateforme standardise le processus de collecte. Les équipes d’annotation classifient et traitent ensuite les données, avant de proposer des services de données d’entraînement aux entreprises d’IA. Aujourd’hui, de nombreux grands modèles de langage, systèmes de reconnaissance d’images et modèles de conduite autonome s’appuient sur des données issues de ces plateformes.
Cette approche constitue la norme dans le secteur de l’IA depuis des années, appréciée pour son efficacité opérationnelle et ses processus de validation éprouvés. Néanmoins, le pouvoir sur les données et la répartition des revenus restent concentrés au sein de la plateforme.
La propriété des données représente l’une des différences majeures entre Caspius et les plateformes de données IA classiques.
Ces dernières adoptent généralement un modèle centralisé : elles collectent, stockent et monétisent les données, laissant les contributeurs sans réelle participation aux flux de valeur ultérieurs.
Caspius, au contraire, privilégie la collaboration ouverte et une logique d’incitation on-chain. En théorie, les contributeurs peuvent non seulement télécharger des données d’entraînement, mais aussi prendre part aux échanges de valeur de l’écosystème via le mécanisme de Token.
Le tableau ci-dessous met en lumière les écarts structurels en matière de données :
| Aspect de comparaison |
Caspius |
Plateformes de données IA classiques |
| Mode de contrôle des données |
Réseau ouvert |
Contrôle centralisé par la plateforme |
| Modèle de contribution |
Collaboration communautaire |
Collecte par l’entreprise |
| Répartition des revenus |
Mécanisme d’incitation on-chain |
Piloté par la plateforme |
| Transparence des données |
Mécanisme vérifiable |
Processus opaques |
| Structure du réseau |
Décentralisée |
Centralisée |
Ces différences placent Caspius plus près de l’économie de données Web3.
Les plateformes de données IA classiques fonctionnent souvent sur un modèle de rémunération fixe. Par exemple, elles paient les collecteurs de données ou les équipes d’annotation, puis revendent les données traitées aux entreprises d’IA.
Caspius, lui, utilise des incitations en Tokens pour accroître l’offre de données. Les utilisateurs qui téléchargent des données d’entraînement valides reçoivent des Tokens CAS, et le réseau attire davantage de contributeurs grâce à des récompenses économiques.
L’avantage clé de ce modèle réside dans la participation ouverte. Contrairement aux plateformes classiques qui s’appuient sur une collecte de données gérée par l’entreprise, Caspius mise sur la collaboration communautaire et des sources de données mondiales.
Cependant, le modèle d’incitation par Token peut être influencé par les cycles du marché, la volatilité du cours du Token et le rythme de développement de l’écosystème. Sa viabilité à long terme reste donc à confirmer.
Les plateformes de données IA classiques sont généralement des systèmes fermés, ce qui empêche les tiers de retracer l’origine des données, les critères de filtrage ou les normes d’audit.
Caspius vise à renforcer la transparence grâce à des mécanismes on-chain. Par exemple, certains traitements de données peuvent inclure des enregistrements on-chain, des contributions vérifiables et des audits communautaires, favorisant ainsi la collaboration ouverte.
La transparence devient cruciale pour les réseaux de données IA. À mesure que les modèles d’IA gagnent en ampleur, le marché accorde une attention croissante à la provenance des données d’entraînement et au contrôle qualité.
Pour les données d’entraînement des robots, les seuls enregistrements on-chain ne suffisent généralement pas à garantir la qualité ; des mécanismes solides de validation des données sont donc indispensables.
Quels défis Caspius doit-il relever ?
Malgré le potentiel de croissance des réseaux de données IA décentralisés, Caspius doit surmonter plusieurs obstacles.
D’abord, l’authenticité. Les données d’entraînement des robots exigent une grande précision ; des données de faible qualité ou falsifiées peuvent compromettre l’apprentissage. Une vérification rigoureuse est donc essentielle.
Ensuite, les questions de confidentialité et de réglementation. Les vidéos et les données comportementales du monde réel peuvent impliquer la vie privée des utilisateurs, la géolocalisation et des réglementations variables selon les régions.
Par ailleurs, les grandes entreprises d’IA possèdent déjà des capacités internes de collecte de données très développées. Il reste à savoir si les réseaux de données ouverts pourront maintenir un avantage concurrentiel à long terme.
En tant qu’actif crypto, la performance de marché du CAS est également soumise aux cycles du secteur et aux fluctuations du marché.
Conclusion
Bien que Caspius et les plateformes de données IA classiques soutiennent tous deux l’entraînement des modèles d’IA, ils divergent nettement sur la structure du réseau de données, la logique de répartition de la valeur et la conception de l’écosystème.
Les plateformes classiques reposent sur une gestion centralisée, tandis que Caspius prône la collaboration ouverte, la contribution communautaire et les incitations on-chain. Avec l’essor rapide de la Robotique IA et de l’IA incarnée, le besoin en données d’entraînement issues du monde réel s’intensifie, et les réseaux de données décentralisés deviennent un élément clé de l’infrastructure IA.
Néanmoins, le marché des données IA continue d’évoluer rapidement. Les enjeux de qualité des données, de conformité réglementaire et de durabilité de l’écosystème resteront des facteurs déterminants pour la trajectoire à long terme du secteur.
FAQ
Que sont les plateformes de données IA classiques ?
Les plateformes de données IA classiques sont généralement exploitées par des entreprises centralisées chargées de la collecte, de l’annotation, de la gestion et de la distribution commerciale des données.
Quelle est la principale différence entre Caspius et les plateformes de données IA classiques ?
La différence majeure réside dans la structure du réseau de données. Caspius met l’accent sur la collaboration ouverte et les incitations on-chain, alors que les plateformes classiques reposent sur une gestion centralisée.
Pourquoi la Robotique IA a-t-elle besoin d’autant de données du monde réel ?
Les systèmes robotiques doivent apprendre l’exécution d’actions, les relations spatiales et l’interaction avec l’environnement. Les seules données textuelles ne suffisent pas pour l’apprentissage de comportements complexes.
Quels sont les risques des réseaux de données IA décentralisés ?
Les réseaux de données décentralisés peuvent être confrontés à des défis liés à l’authenticité des données, à la conformité en matière de confidentialité, à la qualité des données et à la durabilité de l’écosystème.








