在AI模型向多模态、垂直場景與智能體(Agent)演進的過程中,行業共識正從「數據越多越好」轉向「高保真、可溯源、符合隱私合規的數據才是稀缺資源」。傳統中心化標註平台在成本、長尾需求響應與貢獻者權益分配上存在瓶頸;去中心化AI數據網絡嘗試用群體智能、Token協調與開放接口重構數據生產關係。理解Alaya AI如何運作,需要從其技術分層、自動標註管線、採樣邏輯與鏈上經濟機制入手,而非僅將其視為「區塊鏈版標註外包」。
從產業架構視角看,Alaya AI代表Web3與AI在數據層的結合路徑:數據貢獻可激勵、任務權限可NFT化、模型開發可通過AGT質押池獲得社區資助,開放數據平台(ODP)則連接供需雙方。下文將按技術模塊說明該網絡的核心架構、效率提升機制、Web3融合方式、質押與貢獻體系、與傳統平台差異、現實挑戰及未來演進方向,為評估其技術可行性與生態價值提供結構化框架。
Alaya AI的核心技術架構解析
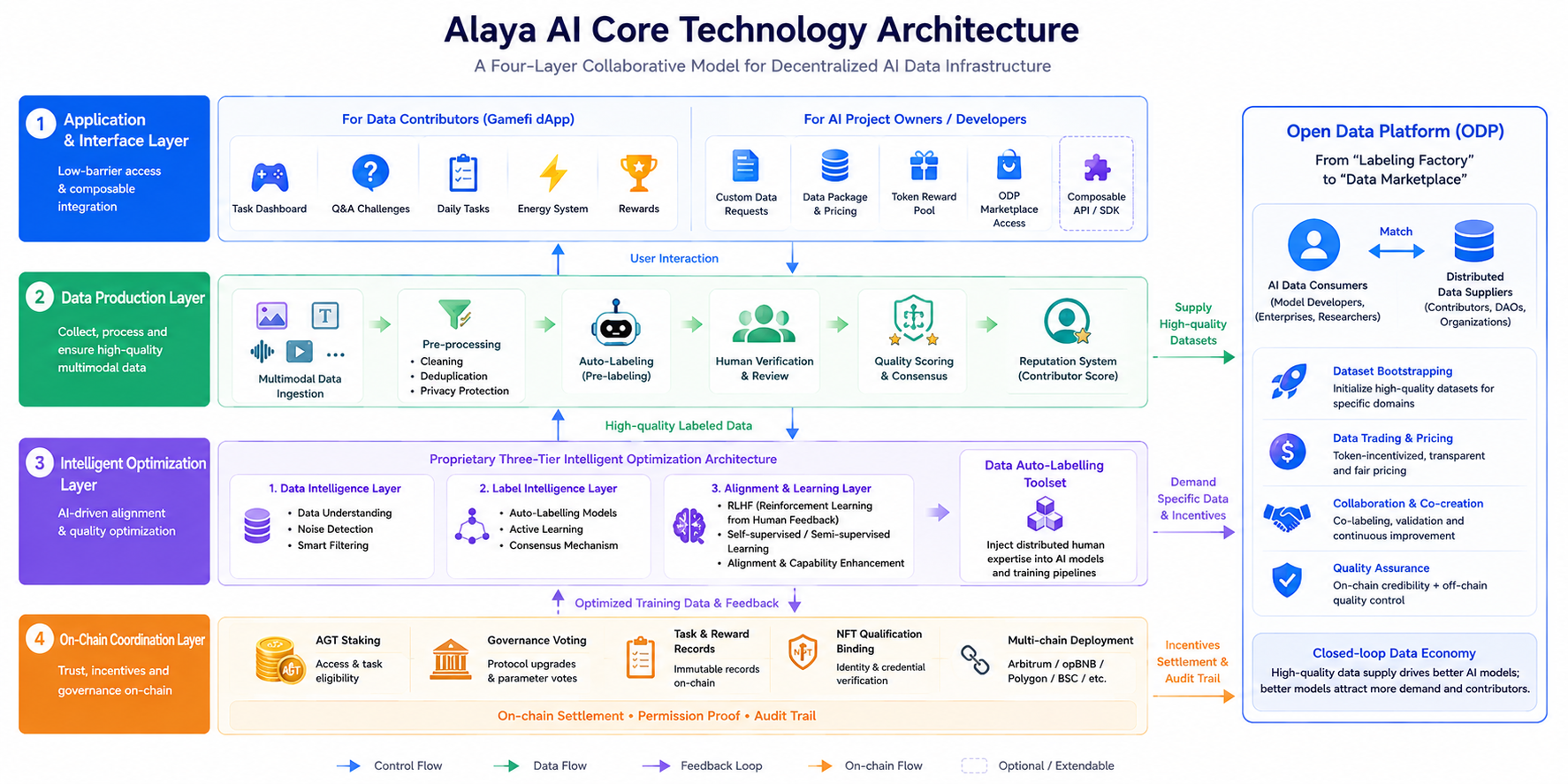
Alaya AI的整體架構可概括為四層協作模型,各層職責分離、數據與控制流清晰,避免「全部上鏈」帶來的性能損耗。
-
應用與接口層。面向數據貢獻者的遊戲化dApp(含任務面板、問答挑戰、每日任務等),以及面向AI項目方的定製數據請求、數據包報價與ODP市場入口。該層強調低門檻參與與可組合接入,使開發者能通過自定義Token獎勵池發布垂直數據需求。
-
數據生產層。負責多模態數據接入(文本、圖像、視頻、音頻)、預處理(清洗、去重、隱私保護)、自動標註、人工校驗與質量評分。官方借鑑群體智能(Swarm Intelligence)原則:同一任務可由多名貢獻者交叉標註,通過共識或多數機制提升標籤一致性,並以歷史準確率形成貢獻者聲譽,影響後續任務分配。
-
智能優化層。核心是proprietary三層智能優化架構驅動的Data Auto-Labelling Toolset(數據自動標註工具集),結合RLHF(Reinforcement Learning from Human Feedback,人類反饋強化學習)微調,把分散的人類專業知識注入自監督與半監督流程,服務對齊(Alignment)與模型能力提升目標。
-
鏈上協調層。AGT質押、治理投票、任務與獎勵狀態記錄、NFT資格綁定等關鍵協調信息依託區塊鏈(生態部署涉及Arbitrum、opBNB、Polygon、BSC等多鏈環境,具體以官方公告為準)。鏈上不承載大體量原始數據,而承擔激勵結算、權限證明與審計軌跡錨定,符合「鏈下計算、鏈上信任」的常見Web3 AI設計範式。
2024年11月推出的Open Data Platform(ODP)在架構上把網絡從「標註工廠」延伸為「數據市場」:AI數據消費者與分佈式供應方通過可定製Token激勵直接對接,支持數據集引導(Bootstrapping)、交易與協作,形成供需閉環。
自動標註系統如何提升AI數據效率
自動標註(Auto-Labeling)是Alaya AI降低邊際成本、縮短交付週期的核心模塊。官方將其定位為自監督AI演進的下一階段:機器先生成候選標籤,人類聚焦歧義樣本與領域判斷,而非對每一條數據從零手寫標註。
技術流程通常包括以下環節:
多模態接入:工具鏈接收靜態與動態視覺數據、文本及傳感類輸入,統一進入預處理管線。
算法預處理:執行自動清洗、去重;對敏感數據路徑應用零知識加密(ZK-encryption),在盡量不暴露明文的前提下完成計算,回應企業客戶對隱私與合規的要求。
模型預標註:基於自研自動標註模型生成初始標籤;對常見AI數據類別,官方稱驗證率可達80%以上,並可實時處理動態視覺流,這對自動駕駛幀標註、工業質檢視頻等場景尤為重要。
RLHF優化循環:將貢獻者校驗結果反饋至模型,持續壓縮人工覆核比例。行業實踐表明,在RLHF閉環下,人工介入可集中於約20%的高難度樣本,從而把整體成本與週期顯著壓低(具體比例因任務類型而異)。
專家真相層(Truth Layer):對企業級高保真訂單,平台可調度內部領域專家團隊(工程師、語言學家、視覺專家等)作為最終仲裁層,與眾包結果形成「自動化吞吐+專家精度」雙軌結構。2026年對外材料亦強調,海量噪聲數據正成為運營瓶頸,高保真垂直數據才是下一代模型與Agent的關鍵燃料。
該混合架構的意義在於:公開網絡負責規模與速度,封閉專家管線負責風險敏感行業的質量底線,避免去中心化被誤解為「低質量眾包」。
分佈式數據採樣機制如何實現
與「全量隨機抓取」不同,Alaya AI強調intelligent optimisation與targeted sampling(定向採樣):根據模型目標篩選高信息密度樣本,緩解「大數據集、低有效信號」問題。
採樣機制可從三個維度理解:
需求驅動:AI客戶提交定製請求(如特定方言、專科醫學影像、區域路況),平台按任務屬性將工作單元路由至具備相應NFT等級、語言或專業背景的貢獻者池,實現人力與任務的近似匹配。
群體冗餘採樣:對同一批次數據安排多人獨立標註,通過一致性檢測識別離群標籤;低一致度樣本自動進入覆核隊列或專家通道,相當於用分佈式冗餘替代單一質檢員全程跟單。
動態與靜態分流:靜態圖像任務與動態視頻流任務採用不同吞吐策略;動態視覺可結合自動分割與幀級標註,降低人工逐幀成本。
時間與場景採樣:官方場景包括利用通勤等碎片時間參與輕量任務,把閒置人力轉化為數據產能;遊戲化UI(經驗值、能量值)維持長期留存,使採樣池具備持續性而非一次性眾包衝刺。
預處理階段的清洗與去重,則從源頭降低採樣偏差——重複樣本、損壞文件、錯誤元數據若進入訓練集,會放大模型幻覺與偏見。採樣因此不僅是「抽多少」,更是「抽什麼、誰來做、如何驗」的系統工程。
Web3與AI網絡如何結合
Alaya AI的Web3屬性並非停留在「用Token發工資」,而是把數據網絡的關鍵協調環節代幣化、NFT化與治理化。
Token協調:原生代幣AGT承擔質押門檻、治理投票、高級任務解鎖、NFT升級及模型質押池資金入口。質押設計強調沉沒成本與安全,官方明確AGT質押本身不提供被動生息,以避免投機資金擾亂標註質量激勵。
NFT權限:Alaya NFT與Medallion NFT構成雙軌身份系統,決定可接任務類型、等級上限與成就體系;高等級升級在特定節點消耗AGT,把鏈上身份與線下勞動產出綁定。
開放激勵組合:項目方可使用AGT或自有Token建立定製數據池,滿足Web3原生AI團隊的結算偏好;中小開發者可通過ODP以較低現金成本引導數據集。
鏈上審計與血緣:對企業客戶,平台強調端到端密碼學完整性與不可篡改審計軌跡,使數據血緣(Data Lineage)可追溯,支撐合規審查。
遊戲化與社會增長:每日任務、推薦佣金、月度AGT Redemption(用戶將任務獲得的AIA積分在固定窗口兌換池內AGT)等機制,把鏈下活躍度週期性映射到鏈上價值分配。
多鏈部署則降低不同生態用戶的friction:同一數據網絡可觸達Arbitrum、opBNB等用戶群,路線圖亦提及擴展BNB Chain、Optimism等,以適配費用與速度差異。
2026年生態論述進一步將Alaya AI定位為AI Agent的數據骨幹:Agent需要持續的人類反饋與niche知識,而Web3眾包+自動標註提供可擴展的反饋管道;與實時交互型Agent框架的協同(如對外討論的OpenClaw類能力)指向「現場學習+大規模verified數據集」雙循環的未來形態。
AI模型質押與數據貢獻體系解析
模型代幣化(AI Model Tokenisation)是Alaya AI區別於一般標註平台的重要機制:社區可通過AGT質押池為特定模型的開發與微調提供資金與數據勞動力,使「誰貢獻數據、誰受益於模型改進」更易對齊。
貢獻者路徑:註冊dApp → 完成基礎任務積累聲譽 → 質押AGT解鎖校驗、校準與自動標註協作等高級任務 → 獲得更高獎勵槓桿;同時賺取AIA積分,參與每月Redemption兌換AGT。
項目方路徑:在平台發布定製數據需求 → 設立AGT或第三方Token獎勵池 → 平台將任務分配給匹配的貢獻者 → 經自動標註與人工質控交付數據集 → 可選在ODP上架或交易。
質押安全邏輯:AGT作為Proof of Stake式協調工具,提高惡意標註與刷量的經濟代價;與Medallion NFT組合後,進一步限制高級任務准入,保護高價值數據訂單。
價值回流:官方規劃將平台數據服務收入用於回購AGT並注入用戶獎勵池,試圖閉合「客戶需求—收入—再激勵—更多高質量數據」的商業飛輪;其實際效果取決於企業訂單規模與回購透明度。
該體系把數據貢獻從一次性勞務變為可參與的網絡協作:貢獻者、質押者與項目方在同一套規則下競爭與協作,這是傳統SaaS標註平台難以原生支持的Web3結構。
Alaya AI與傳統AI數據平台的区别
| 維度 | Alaya AI | 傳統平台(如Scale AI、Labelbox等) |
|---|---|---|
| 組織形態 | 分佈式社區+開放平台 | 中心化運營與企業合同 |
| 激勵 | AGT、AIA、NFT、遊戲化 | primarily 法幣薪酬 |
| 數據定製 | 自定義Token池、P2P請求 | 標準化SLA與採購流程 |
| 所有權表達 | NFT與鏈上記錄強調貢獻權益 | 合同條款約定 |
| 自動化 | 三層自動標註+RLHF+專家覆核 | 成熟流水線,車企等深度垂直案例多 |
| 客戶類型 | Web3原生與中小AI團隊為主,企業拓展中 | 大型科技公司、政府項目佔比高 |
Alaya AI的優勢在於長尾、跨境、快速組池與透明激勵;傳統平台的優勢在於交付確定性、法務成熟度、行業認證與超大規模項目經驗。去中心化網絡並非在所有場景替代中心化供應商,而是在「預算敏感、垂直niche、crypto-native」交叉地帶建立差異化。
此外,Alaya強調高保真垂直數據而非無限堆量,與傳統「大數據集」競爭邏輯不同;這對參數更高效的小模型與Agent更友好,但也要求客戶接受混合管線(自動+專家)的定價與交付模型。
去中心化AI數據網絡面臨哪些挑戰
儘管架構完整,去中心化AI數據網絡仍面臨現實約束。
質量與規模平衡:數百萬註冊用戶中,持續高質量標註者的比例難以從外部直接驗證;若激勵導向刷量,將損害AI客戶續約與網絡聲譽。
企業採納門檻:法務、SOC2、專屬項目經理、事故賠償等是企業採購標配;鏈上透明alone不足以簽下大型合同,需持續積累可審計案例。
用戶體驗複雜度:錢包、NFT、雙Token(AGT/AIA)、質押與Redemption規則提高新用戶學習成本,可能限制非Web3貢獻者流入。
監管不確定性:跨境數據、代幣激勵勞務、醫療等敏感數據的合規要求各國不一;政策變化可能影響運營區域與Token設計。
流動性與激勵可持續:AGT市值與交易量相對大盤仍屬中小級別;若平台收入與回購不及解鎖與兌換供給,激勵可能依賴新增用戶而非內生現金流。
技術風險:智能合約漏洞、錢包綁定錯誤導致無法領取Redemption、自動標註模型在長尾類別誤差放大等問題,都需要持續工程投入。
競爭壓力:中心化巨頭資金雄厚、客戶粘性高;其他Web3數據項目亦在爭奪同一敘事,差異化需用交付數據證明。
Alaya AI技術未來的發展方向
結合官方路線圖與2025–2026年動態,技術演進可能集中在以下方向。
自動標註與RLHF深度整合:提升動態視覺、多語言與Agent反饋類數據的實時處理能力,縮短「採集—標註—部署回模型」週期。
ODP與社交化數據協作:從數據集引導擴展至更活躍的交易、共享與協作功能,提高網絡效應。
DAO與治理完善:將自動標註功能優先級、經濟參數等更多決策交由AGT質押者投票,增強社區主權敘事可信度。
多鏈與算力生態協同:與DePIN、去中心化算力(如Akash、Golem)及模型市場協議(如Bittensor)對接,探索「數據—訓練—推理」開放棧,減少單一平台鎖定。
Agent時代定位:持續強化高保真、人類在回路(Human-in-the-Loop)數據作為Agent推理骨幹;與實時Agent學習框架協同,形成快慢雙循環。
企業合規增強:擴展ZK加密、血緣審計與專家覆核覆蓋,爭取醫療、金融等強監管行業訂單。
2026年每月AGT Redemption等機制表明,運營側正通過固定節奏維持貢獻者預期;技術側能否匹配運營節奏,取決於自動標註準確率、任務路由算法與專家層的持續投入。
總結
Alaya AI的去中心化AI數據網絡,本質上是分層協作系統:應用層降低參與門檻,數據生產層以自動標註與分佈式採樣提升效率,智能優化層以RLHF吸收人類知識,鏈上協調層以AGT、NFT與治理規則對齊激勵與安全。Open Data Platform把網絡從任務平台升級為可組合的數據市場,模型質押池則把社區資金與勞動力引入模型微調閉環。
其運作邏輯對AI產業的意義在於:當高質量垂直數據成為瓶頸時,僅靠中心化採購難以覆蓋長尾與全球碎片人力;Web3架構提供另一種供給曲線。與此同時,挑戰同樣真實——質量驗證、企業SLA、監管與激勵可持續性,將決定該技術架構能否從「可演示」走向「可規模商業化」。
對技術觀察者而言,評估Alaya AI不應只看鏈上交易量或用戶註冊數,更應跟踪自動標註驗證率、ODP成交、企業客戶復購與回購執行等硬指標。這些指標共同回答一個問題:去中心化AI數據網絡,是否能在效率與可信度上同時跑贏傳統平台的核心優勢領域。
分享
目錄


相關文章

Solana需要 L2 和應用程式鏈?

Sui:使用者如何利用其速度、安全性和可擴充性?

Morpho 代幣經濟學深入解析:MORPHO 的應用、分配方式與價值邏輯

Morpho vs Aave:深入解析 DeFi 借貸協議的機制與結構差異

USD.AI 效益來源解析:AI 基礎設施貸款如何創造收益
