AIがトレーディングワークフローに組み込まれる6つのポイント——支援と代替の線引き
AIが情報収集、仮説立案、バックテスト、リスクコントロール、レビュー、実行検証の6つの役割を果たすことを概説し、各ステップにおいてAIが支援可能な部分と、最終的な人間による判断が必要な部分を明確にします。
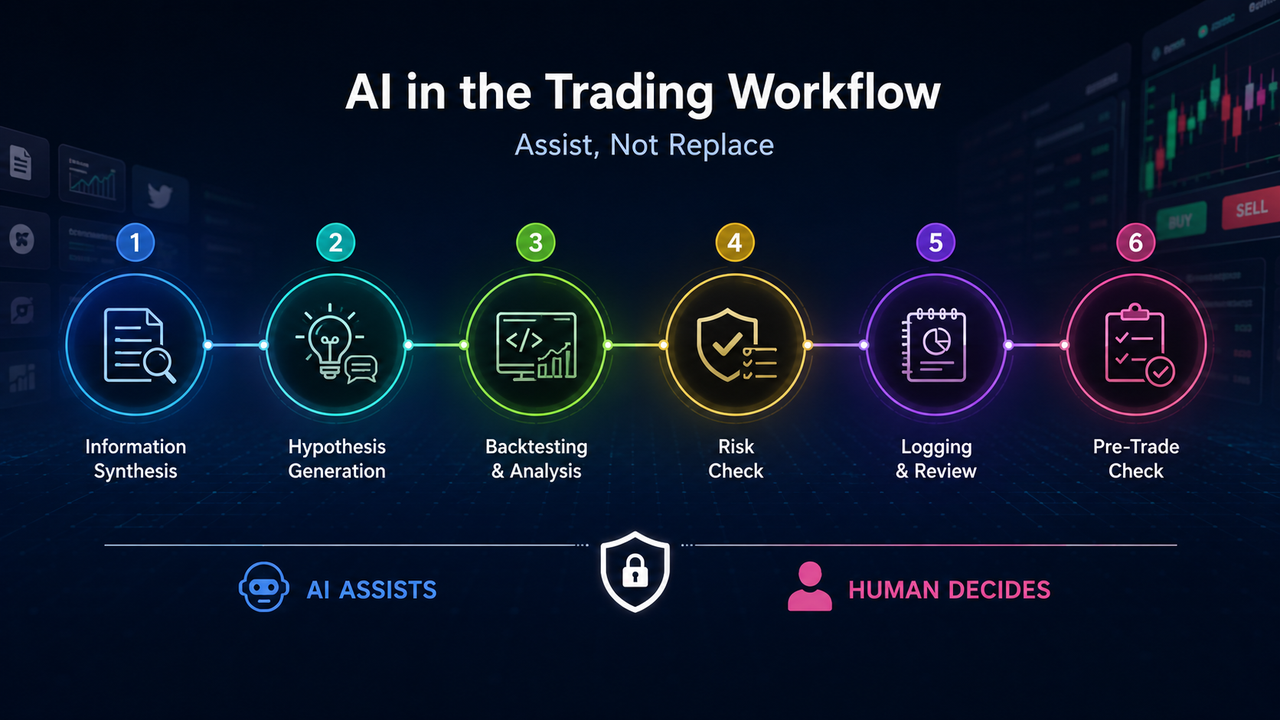
1. 出発点:なぜ「モデル」より先に「境界」を議論するのか
暗号資産市場は、ボラティリティの高さ、多様なデータソース、高速な取引執行により、情報処理に常に大きなコストがかかります。この分野に人工知能(AI)が導入されると、往々にして「リサーチとタイミングを代替するインテリジェントトレーダー」として期待されるか、あるいは「ライブ取引には無関係なチャットツール」として軽視されるかの二極対立に陥ります。どちらの極端な見方も、持続可能なワークフローの構築を妨げます。
より実践的な視点は、AIを取引プロセスにおける補助ノードと捉え、主たる意思決定者とは見なさないことです。ノードは情報整理の迅速化、直感を検証可能な仮説へ変換、バックテストコードフレームワークの生成、リスク管理チェックリストのクロスチェック、レビュー記録の整理、発注前の計画の反復精査などに貢献します。ただし、情報源の信頼性検証、統計の妥当性確認、ポジション責任の遂行、取引執行は人間の側に残すべきです。本レッスンの目的は、特定の製品を紹介したり、秘訣を伝授することではなく、まずワークフローを明確にし、間違った段階で過度に委任することを防ぐことにあります。
2. ワークフロー分解:6つのポジションとその機能的特性
リサーチから執行、レビューに至るサイクルを分解すると、AIは以下の6つのポジションに最も適切に適合します。各ポジションは、異なる入力、出力、リスクの種類に対応しています。
-
ポジション1:情報整理。 市場情報は、取引所の発表、プロジェクト文書、オンチェーンデータ、マクロ経済カレンダー、ソーシャルメディアに散在しています。AIはこれを時系列で集約し、要約し、異なる情報源からの記述を juxtapose(並置)することができます。ここでの出力は常に「検証待ちのドラフト」であり、事実確認ではありません。要約は元の情報源と日付、コンテクストを明示しなければならず、情報源のない記述を取引の根拠にしてはなりません。
-
ポジション2:仮説生成。 取引はしばしば、議論の余地のある判断(特定のマクロ環境におけるボラティリティ上昇や、特定の資産クラスの相対的な強さなど)から始まります。AIは漠然としたアイデアを、「Aが成立すればBを予想、Cが発生すれば仮説は失敗」といった構造に変換し、必要なデータフィールドを列挙できます。仮説の価値は反証可能性にあります。一定期間内にデータで検証できないナラティブはリサーチの段階に留め、ポジション決定の根拠にしてはなりません。
-
ポジション3:バックテストと統計的サポート。 AIはバックテストコードの生成、シャープレシオや最大ドローダウンといった指標の説明、一般的な統計的落とし穴の指摘に適しています。しかし、データクリーニングが正しいか、上場廃止銘柄が含まれているか、手数料や資金調達レートが考慮されているか、先見バイアスがないかといった点は、すべて独立した監査が必要です。コードが実行されることは構文の正しさを確認するだけで、戦略の健全性を検証するものではありません。
-
ポジション4:リスク管理チェック。 1取引あたりのリスク制限、レバレッジ上限、主要データ発表への近接性などは、取引前チェックリストとしてまとめ、AIが現在のポジションや計画と照合できます。リスク管理の本質はハードな制約であり、AIは注意喚起や列挙はできても、長期的な検証なしに自動承認するべきではありません。パラメータが現在のボラティリティに適合するか、逆風下で拒否権が適切に行使されるかは、人間の判断に委ねられるべきです。
-
ポジション5:記録とレビュー。 散在したメモは統一形式に整理し、エラータイプで分類し、「計画対実績」と比較できます。レビューは記憶ではなく実際の取引記録に基づくべきであり、改善点は少数かつ実行可能であるべきで、戦略の失敗と執行の失敗を区別する必要があります。レビューの目的はワークフローの反復改善であり、事後的な合理化ではありません。
-
ポジション6:執行前確認。 ターミナルで発注する前に、方向性、数量、ストップロス、証拠金モード、ポジション削減のみであるかを再確認し、イベントカレンダーや現在の保有状況との矛盾をチェックします。執行エラーは最もコストが高く、AIは見落としを減らせても、クリックや責任負担を代替することはできません。
3. 補助 vs 代替:分業の制度的含意
これら6つのポジションは、一つの原則を形成します。AIは情報と計算能力を拡張できても、アカウントの管理権限を掌握すべきではないということです。以下の表は技術的な限界ではなく、責任構造を反映しています。
-
情報整理において、AIは要約とフォーマットを担当し、人間は情報源の信頼性と時系列を検証します。
-
仮説生成において、AIは構造化された記述を提供し、人間は取引の実行可否とポジション制限を決定します。
-
バックテストにおいて、AIはフレームワークと説明を提供し、人間はデータ、手数料、サンプル外検証を管理します。
-
リスク管理において、AIはチェックリストをスキャンし、人間は拒否権を行使し、パラメータの適合性を判断します。
-
レビューにおいて、AIは記録をフォーマットし、人間は記録の信頼性を確保し、改善アクションを実行します。
-
執行において、AIは計画を再確認し、人間はターミナルで最終確認を行います。
検証を省略し、モデル主導の結論を直接採用することは、通常、証拠の連鎖を流暢な言語で代替することになります。「素晴らしいバックテスト結果」を、付随するデータや手数料の前提なしに信頼することは、ナラティブを結果と見なすことです。確認なしにAPIや自動化スクリプトに無制限のアクセス権限を与えることは、運用リスクを増大させます。これらの誤用パターンは後続のレッスンで議論されます。
4. 暗号資産シナリオで境界問題が増幅される理由
伝統的な株式リサーチと比較して、暗号資産データはノイズレベルが高く、オンチェーンタグにソーシャルメディア情報が混在し、偽ニュースや古い画像の再利用が一般的です。市場は急速に変動し、流動性やルールが短期間で変化することがあります。ツールチェーンは取引所、オンチェーンプラットフォーム、デリバティブにまたがり、指標はプラットフォーム間で異なる場合があります。自動化の閾値は低く、一度スクリプトの権限が過剰になると、エラーが連続して発生する可能性があります。
したがって、暗号資産シナリオでは、「モデルは十分に強力か」が主要な問いではなく、「どのステップでそれを使用し、どの手動ゲートを維持するか」がより重要です。本レッスンは、データ品質、バックテストの規律、イベント解釈、自動化の安全性に関する後続の議論の基盤を確立します。
5. レッスンサマリー
-
取引におけるAIの適切な役割はワークフローの補助であり、意思決定の代替ではありません。
-
6つのポジションは、情報整理、仮説生成、バックテストサポート、リスク管理チェック、記録/レビュー、執行前確認に対応し、それぞれ明確な責任分担があります。
-
暗号資産市場の高いノイズレベルと速いペースは、モデル選択よりも境界管理をより重要にします。
この分業構造を理解することは、エラーを増幅させることなくAIをワークフローに統合するために不可欠です。次回のレッスンでは、入力データのグレーディング方法、プロンプトによる出力形式の制約、未検証の要約を取引の根拠として使用しない方法についてさらに議論します。
関連コース

暗号資産におけるアイデンティティ:主なプロジェクト

マスターノードトークンの紹介

分散型アイデンティティの基礎

暗号デリバティブ:主なプロジェクト

暗号資産における自分自身の調査(DYOR)を行う
