戦略検証:バックテスト、統計、AI分業
この章では、AIが果たす補助的な役割と、戦略をアイデアから具体的な数値にする過程で必ず維持すべき手動監査の手順について解説します。具体的には、データクレンジング、先読みバイアス、コストの前提条件、そしてアウト・オブ・サンプルテストに焦点を当てます。
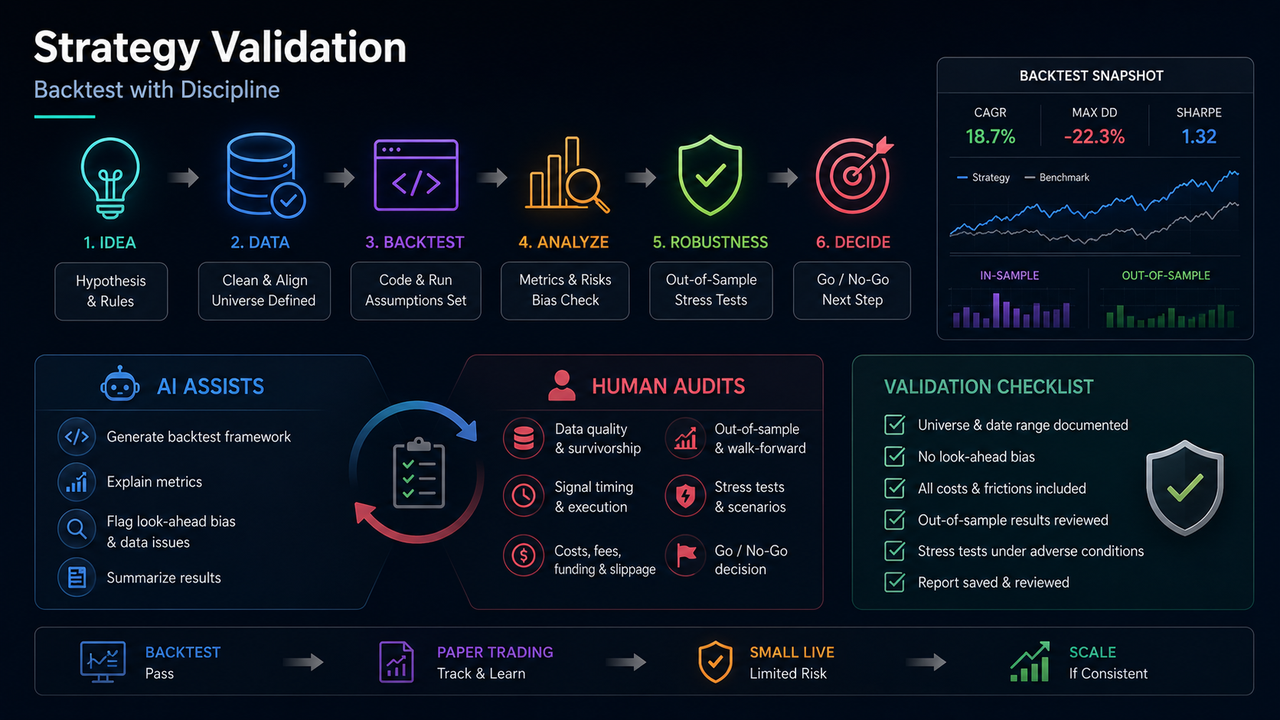
1. 出発点:検証の目的は「収益性の証明」ではない
前回までの2回のレッスンでは、ワークフローにおける分業と入力構造について解説しました。第3回では、アイデアが歴史的な一貫性を示すかどうかに焦点を移します。多くの失敗は方向性そのものが根本的に誤っていることに起因するのではなく、バックテストを適切な監査なしに結論として扱うことから生じます。例えば、データに上場廃止された資産が含まれている、シグナルが未来情報を利用している、コストが省略されている、パラメータが短いサンプルで繰り返し調整されているといったケースです。AIはコード作成やインジケーターの解釈を高速化できますが、戦略が有効かどうかの最終判断は下せません。検証のより合理的な目的は、明確な前提のもとで、戦略が統計的またはコスト面で反証されていないことを確認することです、滑らかなナラティブで不可避の収益性を証明することではありません。
2. バックテストにおけるAIの合理的な分業
AIは以下の補助に適しています。
-
バックテストフレームワークのコード生成
-
シャープレシオ、最大ドローダウン、勝率の意味の説明
-
将来バイアスの可能性があるポイントの一覧化
-
結果表をテキストサマリーに整理
人間が独立して完了またはレビューすべきタスクは以下のとおりです。
-
ユニバースにサバイバー(生存バイアス)が含まれていないか
-
上場前に価格が存在していたか
-
手数料、スリッページ、資金調達率が含まれているか
-
アウトオブサンプルテストやウォークフォワードテストが実施されているか
-
ペーパートレードとライブトレードの乖離が考慮されているか
コードが実行されたということはエンジニアリング上のステップが完了したことを示すだけであり、戦略が検証に合格したことを意味しません。
3. データクリーニング:暗号資産バックテストで最も脆弱な工程
バックテストで現在もアクティブなトークンだけを使用すると、結果は系統的に楽観的になる傾向があります。トークン上場前の期間は取引可能と見なすべきではありません。価格、出来高、資金調達率は取引所によって異なります。バックテストでは取引所を固定するか、合成ルールを明示する必要があります。フォーク、コントラクト移行、トークン名称変更は価格系列の途切れを引き起こし、手動マッピングまたは除外が必要です。デペッグ期間中に単一のステーブルコインを価格に使用すると、リターンとリスク指標が歪む可能性があります。主要なデペッグ期間は別途マークするか説明すべきです。AIはドキュメント内でデータソース、時間範囲、ユニバースの定義を明示し、各項目を生データと突き合わせて確認するよう要求されるべきであり、単にバックテストカーブを追いかけるよりも重要です。
4. 将来バイアス:シグナルと実行の時間軸の整合性
よくある将来バイアスには以下があります。
-
正規化に全サンプルの統計量を使用し、同じ全サンプルでバックテストする
-
終値でシグナルを生成し、翌日の寄り付きで実行する
-
事後的にのみ「スマートマネー」とラベル付けされたアドレスを使用する
-
修正されたマクロデータをあたかも当初の発表値であるかのように使用する
規律として明示すべきこと:t時点で生成されたシグナルは、戦略タイプに応じてt+1以降に実行されなければならない。マクロデータを当初リリースされた形で入手できない場合、関連する結論は格下げすべきである。AIはコードコメント内で各特徴量のデータ利用可能タイミングを注釈するよう要求できる。人間は主要な特徴量が実行の少なくとも1日前に先行しているかをスポットチェックすべきである。
5. コストと摩擦:手数料なしのバックテストはデフォルトで無効
暗号資産戦略には少なくとも取引手数料、スリッページ、無期限資金調達率(ポジションが決済ポイントをまたぐ場合)、借入金利(レバレッジ使用時)、および必要に応じて引き出し/クロスチェーンコストを含めるべきです。ベースラインと悲観的な手数料シナリオ(例:手数料2倍)をストレステストに使用できます。期待リターンが悲観的シナリオで急激に悪化するかマイナスになる場合、その戦略はコスト感応度が高く、サンプル内カーブだけで判断すべきではありません。AIはしばしば手数料をゼロまたは1ベーシスポイントにデフォルト設定します。人間はバックテストの前提とレポートに手数料テーブルを明記しなければなりません。
6. オーバーフィッティングとアウトオブサンプル:パラメータ増加はナラティブの慎重さを要求
症状には以下があります。
-
多数のインジケーターセットのうち最良の組み合わせのみを提示
-
短期間の強気相場サンプルでのみパラメータ調整
-
メカニズム説明のない高度に特化したルール
対策には以下があります。
-
パラメータチューニングに使用しないアウトオブサンプル期間を確保
-
ローリングウィンドウのウォークフォワードテストを適用
-
説明可能な前提の範囲内でルールを可能な限り簡素化
レポートではサンプル内とサンプル外の両方の主要指標を提示すべきです。サンプル外のパフォーマンスがサンプル内より著しく劣る場合、オーバーフィッティングリスクをフラグし、ライブスケーリングを停止すべきです。AIはカーブが良好に見えるまで無監視でパラメータを繰り返し最適化すべきではありません。それは自動化されたオーバーフィッティングに等しいからです。
7. バックテストからライブ取引へ:ワンステップ起動ではなく段階的前進
3段階のラダーを推奨します。第一段階:文書化されたユニバース、手数料、アウトオブサンプル結果でバックテスト合格。第二段階:ペーパーまたはシミュレーション取引記録でシグナル/実行価格の乖離を確認し、実際のスリッページを観察。第三段階:制限付き・ストップロス付きの小規模ライブ取引を行い、ペーパーとライブの結果を継続的に比較。各段階への進級は人間が決定します。モデルが大口ポジションを推奨するのではありません。AIは各段階のチェックリストを生成できますが、進級判断を代替することはできません。
8. バックテストレポートの最低限の項目
複雑なシステムがなくても、レポートには以下を含めるべきです。
-
一文の戦略説明
-
データ期間と資産範囲
-
手数料前提テーブル
-
サンプル内およびサンプル外のリターン、最大ドローダウン、取引回数
-
最大連続損失
-
未解決の問題のリスト
-
継続検証、一時停止、または中止の結論
「慎重ながら楽観的」などの行動指針にならない表現は避けてください。バックテストとレビューは同じ規律、すなわち実行可能、監査可能、再現可能を共有します。
9. レッスンのまとめ
今回のレッスンは、アイデアが実際にテストされたかどうかに焦点を当てました。AIはバックテストコードの作成支援、インジケーターの説明、将来バイアスや手数料欠落のフラグ付けに適しています。一方、データ内の生存バイアス、シグナル/実行の整合性、アウトオブサンプルパフォーマンス、悲観的コスト下でのマージンの人間による確認を代替することはできません。コードが実行され、サンプル内カーブが良好に見えることは、エンジニアリングステップが完了したことを意味するにすぎず、ライブスケーリングが正当化されたことを意味しません。より安全な道筋は、バックテストを文書化し、その後ペーパーで追跡し、小規模なトライアルアンドエラーを行うことです。各ステップの前進は人間が決定します。次回のレッスンでは、マクロおよび主要なオンチェーンイベントを取り上げます。これらは最も情報量が多い一方で、結論に向けたサマリーを誤らせやすい時期でもあり、AIが準備を支援できる範囲と、検証において代替できない範囲の明確な境界線が必要です。
関連コース

暗号資産におけるアイデンティティ:主なプロジェクト

マスターノードトークンの紹介

分散型アイデンティティの基礎

暗号デリバティブ:主なプロジェクト

暗号資産における自分自身の調査(DYOR)を行う
