AI 在交易链路的六个位置——辅助与替代的边界
梳理 AI 在信息、假设、回测、风控、复盘与执行核对中的六种角色,明确哪些环节可辅助、哪些必须由人做最终决策。
一、问题起点:为什么讨论“边界“先于讨论“模型“
加密市场的高波动、多数据源与快节奏执行,使信息处理成本长期偏高。人工智能进入这一领域后,常被赋予两种互相对立的期待:要么被视为能够替代研究与择时的“智能交易员“,要么被贬低为与实盘无关的聊天工具。两种极端都不利于建立可持续的工作方式。
更贴近实务的视角,是把 AI 视为交易流程中的辅助节点,而不是决策主体。节点可以加速信息整理、帮助把直觉写成可检验的假设、生成回测代码框架、对照风控清单、整理复盘记录,并在下单前复述计划;但来源真伪、统计是否成立、是否承担仓位与点击下单的责任,仍应留在人工一侧。第一课的任务,不是介绍具体产品或提示技巧,而是先画出一张链路地图,避免在错误环节过度授权。
二、链路划分:六个位置及其功能属性
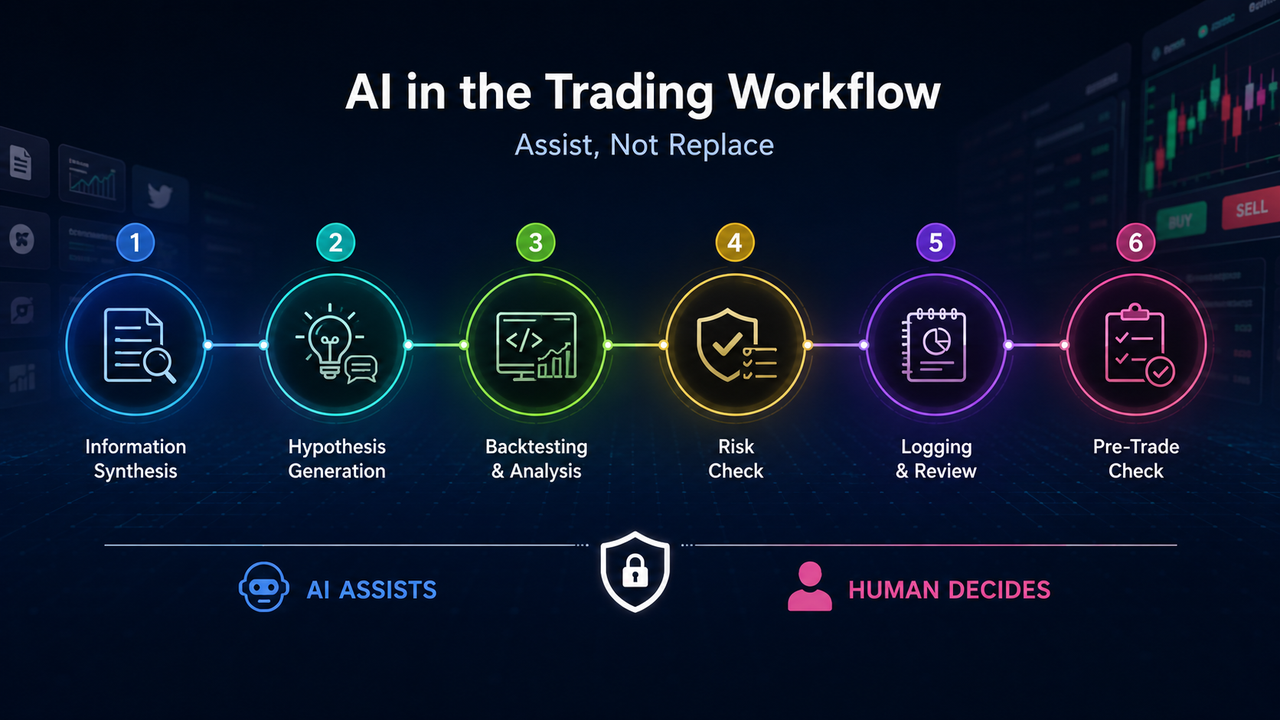
若将一次从研究到执行再到复盘的周期拆开,AI 较适合落在以下六个位置。每一位置都对应不同的输入、输出与风险类型。
-
位置一:信息整理。市场信息分散在交易所公告、项目文档、链上数据、宏观日历与社交媒体之中。AI 可以按时间线汇总、做摘要、并列不同来源的说法。但这一位置的输出默认是“待核实草稿“,不是事实认定。摘要必须能回溯到一手来源,并标注日期与口径;无法附出来源的陈述,不应进入交易理由。
-
位置二:假设生成。交易往往始于一个可讨论的判断,例如某种宏观环境下波动率上升、某类资产相对强势。AI 可以把模糊想法写成“若 A 成立,则预期 B;若 C 出现,则假设失效“的结构,并列出需要补充的数据字段。假设的价值在于可证伪;不能在未来一段时间内用数据检验的叙事,应停留在研究层,而不进入仓位决策。
-
位置三:回测与统计辅助。AI 适合生成回测代码、解释夏普比率与最大回撤等指标、提示常见统计陷阱。但数据清洗是否正确、是否包含已退市资产、手续费与资金费率是否计入、是否存在前视偏差,需要独立审计。代码能够运行,只说明语法无误,并不说明策略成立。
-
位置四:风控检查。可以把单笔风险上限、杠杆上限、重大数据窗口是否临近等,整理成开仓前清单,由 AI 对照持仓与计划做扫描。风控的本质是硬约束;AI 适合提醒与列举,不适合在无长期验证的前提下自动放行。参数是否仍适应当前波动环境,以及是否在恶劣环境下行使否决权,必须保留人工判断。
-
位置五:日志与复盘。零散笔记可以整理为统一格式,按错误类型归类,并对比“计划与实际“的差异。复盘应基于真实成交记录,而不是记忆;改进项宜少而可执行,区分策略失效与执行失效。复盘的目标是流程迭代,而不是生成看似专业的事后解释。
-
位置六:执行前核对。在终端下单前,复述方向、数量、止损、保证金模式与是否仅减仓,检查是否与事件日历、现有持仓冲突。执行层错误成本最高;AI 可以降低遗漏,不能替代点击与责任承担。
三、辅助与替代:分工的制度含义
六个位置共同构成一条原则:AI 可以扩展信息与计算能力,但不应承接账户能力。下表所表达的不是技术限制,而是责任结构。
-
信息整理环节,AI 负责摘要与编排,人负责真伪与时效。
-
假设环节,AI 负责结构化表述,人决定是否交易及仓位上限。
-
回测环节,AI 负责框架与说明,人负责数据、费用与样本外检验。
-
风控环节,AI 负责清单扫描,人负责否决与参数适用性。
-
复盘环节,AI 负责格式化,人负责记录真实性与改进行动。
-
执行环节,AI 负责计划复述,人负责终端确认。
若跳过核对直接采用模型给出的方向性结论,往往是在用流畅语言替代证据链;若在未附数据与费用假设的情况下相信“回测很好“,属于把叙事当作结果;若将 API 与自动化脚本置于无限额、无确认的状态,则会把操作风险成倍放大。这些误用模式在后续课程中会分别展开。
四、加密场景为何放大边界问题
与传统股票研究相比,加密数据噪声更高,链上标签与社媒信息混杂,假新闻与旧图新用并不罕见。市场节奏快,流动性与规则可在短窗口内切换。工具链横跨交易所、链上与衍生品,同一指标在不同平台的口径可能不一致。自动化门槛相对较低,脚本权限一旦过大,错误会被连续执行。
因此,在加密场景下,“模型是否足够强“并非首要问题;“在哪个环节使用、保留哪些人工闸门“更为关键。第一课建立的,是后续讨论数据质量、回测纪律、事件解读与自动化安全的前提。
五、本课总结
-
AI 在交易中的正确定位是链路辅助,而非决策替代;
-
六个位置分别对应信息、假设、回测、风控、复盘与执行核对,责任分工不同;
-
加密市场的高噪声与快节奏,使边界管理优先于模型选择。
理解这一分工结构,是后续把 AI 纳入工作流而不放大错误的前提。下一课将进一步讨论:输入数据如何分级、提示如何约束输出形态,以及如何避免把未验证摘要当作交易依据。
相关课程

Aethir 介绍

加密货币领域的身份验证项目概览

加密领域自主研究指南(DYOR)
稳定币基础

解析 L1 区块链:Kaia