策略验证——回测、统计与 AI 的分工
本章说明在策略从想法走向数字的过程中,AI 可承担的辅助职能与必须保留的人工审计环节,重点讨论数据清洗、前视偏差、成本假设与样本外检验。
一、问题起点:验证的目标不是“证明能赚钱“
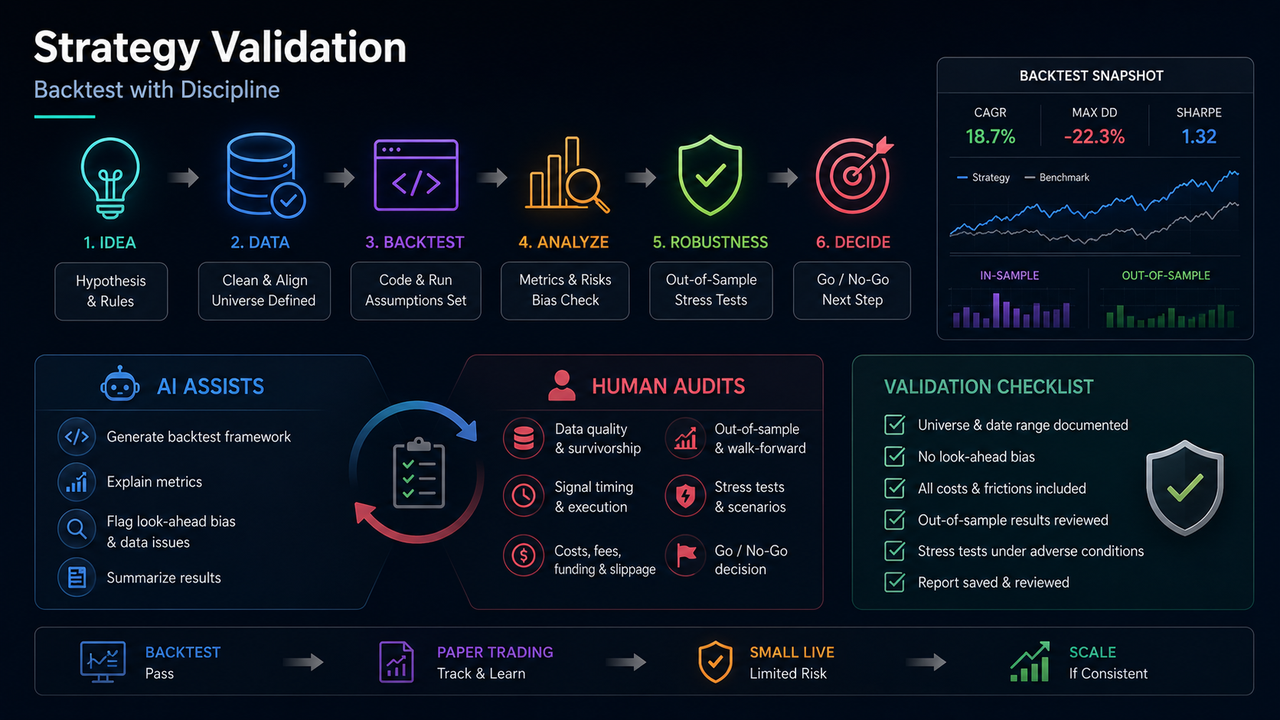
前两课分别处理了链路分工与输入结构。第三课进入“想法是否具有历史一致性“这一环节。许多失败并非源于方向完全错误,而是源于回测在未经审计的情况下被当作结论:数据包含已退市资产、信号使用了未来信息、费用被省略、参数在短样本上被反复调试。AI 可以加速代码编写与指标解释,但不能承接“策略是否成立“的最终判断。验证的更合理目标是:在明确前提下,策略尚未被统计与成本假设证伪;而非用流畅叙述证明必然盈利。
二、AI 在回测中的合理分工
适合由 AI 协助的部分包括:生成回测框架代码、说明夏普比率、最大回撤、胜率等指标含义、列举可能的前视偏差点、将结果表格整理为文字摘要。必须由人工独立完成或复核的部分包括:标的宇宙是否包含幸存者、上币前是否存在价格、手续费与滑点及资金费率是否计入、样本外或走样本检验是否执行、是否将纸面与实盘差异纳入评估。代码能够运行,仅表示工程步骤完成,不表示策略通过验证。
三、数据清洗:加密回测最易失效的环节
回测若只使用当前仍存在的币种,结果往往系统性偏乐观。代币上市前的区间不应纳入可交易假设。不同交易所的价格、成交量与资金费率存在差异,回测应固定交易所或写明合成规则。分叉、合约迁移与代币更名会导致价格序列断裂,需人工映射或剔除。稳定币脱锚阶段用单一稳定币计价,可能扭曲收益与风险指标,重大脱锚窗口应单独标注或说明处理方式。要求 AI 在文档中列出数据源、时间范围与 universe 定义,并对照原始数据逐项勾选,比单纯追求回测曲线更为重要。
四、前视偏差:信号与成交的时间对齐
常见前视包括:用全样本统计量做标准化却在全样本上回测;当日收盘产生信号却在当日开盘成交;使用事后才被标记为“聪明钱“的地址;用修订后的宏观数据冒充历史发布值。纪律上应明确:信号在 t 生成,成交至少在 t+1 或按策略类型更晚;宏观数据若无法获得当时版本,相关结论应降级。可要求 AI 在代码注释中标注每个特征的数据可用时点,人工抽查关键特征是否早于成交一日以上。
五、成本与摩擦:未含费用的回测默认无效
加密策略至少应纳入交易手续费、滑点、永续资金费率(若持仓跨结算点)、借贷利率(若使用杠杆)及必要时提币与跨链成本。可设基础费用情景与悲观情景(例如费用加倍)做压力测试。若悲观情景下期望收益明显恶化或转为负值,说明策略对成本高度敏感,不宜仅凭样本内曲线判断。AI 常默认零费用或单一基点,人工须将费用表写入回测假设并写入报告。
六、过拟合与样本外:参数越多,叙事越需谨慎
征象包括:大量指标组合后只展示最优一组、仅在短牛市样本上调参、规则极度具体却缺乏机制解释。
对抗方式包括:保留不参与调参的样本外区间;采用滚动窗口的走样本检验;在可解释前提下尽量简化规则。
可要求报告同时给出样本内与样本外关键指标;若样本外显著弱于样本内,应标注过拟合风险,并暂停实盘放大。AI 不宜在无人监督的情况下反复优化参数直至曲线满意,那相当于自动化过拟合。
七、从回测到实盘:分级晋级而非一步到位
建议采用三级阶梯。第一级:回测通过,且文档化 universe、费用与样本外结果。第二级:纸面或模拟运行,记录信号与成交价差异,观察滑点现实。第三级:小仓位实盘,设限额与止损,持续对比纸面与实盘。每一级是否晋级由人决定,不由模型建议重仓。AI 可为每一级生成检查表,但不能替代晋级判断。
八、回测报告的最低字段
即使不依赖复杂系统,报告也应包含:策略一句话描述;数据区间与标的范围;费用假设表;样本内与样本外的收益、最大回撤、交易次数;最大连续亏损;尚未解决的问题列表;结论为继续验证、暂停或放弃。避免使用“谨慎乐观“等无法指导行为的表述。复盘与回测共用同一纪律:可执行、可核对、可重复。
九、本课总结
本课围绕“想法有没有经过检验“展开。AI 适合帮忙写回测代码、解释指标、提醒前视偏差和费用遗漏;不适合代替人确认数据是否含幸存者偏差、信号与成交是否对齐、样本外是否还能看、悲观成本下是否仍有余地。代码跑通、样本内曲线好看,都只说明工程步骤走完了,不说明可以放大实盘。更稳妥的路径是回测文档化之后纸面跟踪,再小仓试错,每一级是否往上走由人决定。下一课看宏观和链上重大事件:那时信息最多、也最容易把摘要当成结论,需要单独划清 AI 能协助准备什么、不能代替核实什么。
相关课程

Aethir 介绍

加密货币领域的身份验证项目概览

加密领域自主研究指南(DYOR)
稳定币基础

解析 L1 区块链:Kaia